
注意:本文为该系类文章中(1)和(2)之间的过渡
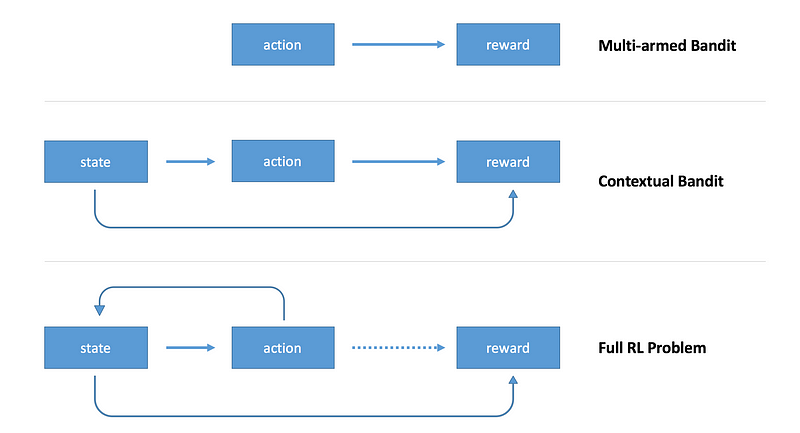
在上一篇文章中我们简要介绍了强化学习并构建了一个简单的agent来解决多臂赌博机问题。在多臂赌博机问题中agent不需要考虑所处环境的状态,只要通过学习确定那一个行动是最优的即可。在不考虑环境状态时,任一时间点上的最优决策是所有时刻最优的决策。在本文结束后,我们会建立一个完备的强化学习问题:问题中存在环境状态并且下一时刻的状态取决于上一步的行动,决策的收益也是延迟发放的。
从无状态的场景迁移到完备的强化学习需要解决很多问题,下面我将提供一个实例并展示如何解决它。希望新接触到强化学习的同学可以从这个过程中有所收获。本文中我将着重讲解什么是状态,但本文中的状态不是由之前的状态和行动决定的。延迟收益的问题本文也不做讨论,这两个问题都将留到下篇文章解决。本文这种强化学习问题的简化版本又被称为上下文赌博机问题。
上下文赌博机
在上文讨论的多臂赌博机问题中,我们只有一个赌博机,可以理解为一台老虎机。agent的决策范围只是选择多个的赌博机臂中的一个,不同的决策对应获得+1或-1收益概率的不同。当我们的agent总是选择获得正收益概率最大的机臂时,我们认为这个问题得到了解决。因为所有的决策和结果都不会影响环境状态,所以我们在设计agent的时候忽略了环境状态。
上下文赌博机引入了 状态 的概念。agent可以利用状态中对环境的表述作出更加明智的决策。在引入这个概念之后,我们把之前的单个赌博机扩展为多个赌博机。环境状态可以告诉我们我们当前使用的是什么样的赌博机,这个agent的目标从对单个赌博机作出最优决策变为对任意数量的赌博机作出最优决策。因为不同赌博机的赌博机臂会有不同的赔率,所以我们的agent需要基于环境状态作出决策,否则它不能在所有的情况下都获得最大的收益。为了解决这一问题,我们将用TensorFlow构架一个单层神经网络来接受状态变量并作出相应行动。通过策略梯度的更新方法,我们可以使网络学会作出收益最大的行动。下面给出示例代码:
|
|
|
|
希望这篇文章可以帮助你直观地理解强化学习中agent如何处理复杂的交互问题。掌握本文中的内容之后,你可以在下一篇文章中进一步探索时间和行为共同作用的问题。
系列文章(翻译进度):
- (0) Q-Learning的查找表实现和神经网络实现
- (1) 双臂赌博机
- (1.5) — 上下文赌博机
- Part 2 — Policy-Based Agents
- Part 3 — Model-Based RL
- Part 4 — Deep Q-Networks and Beyond
- Part 5 — Visualizing an Agent’s Thoughts and Actions
- Part 6 — Partial Observability and Deep Recurrent Q-Networks
- Part 7 — Action-Selection Strategies for Exploration
- Part 8 — Asynchronous Actor-Critic Agents (A3C)

