在最近的黑客马拉松中,我们在STATWORX上进行协作,团队的一些成员利用Google Finance API抓取了每分钟的标准普尔500指数。除了标准普尔500指数以外,我们还收集了其对应的500家公司的股价。在得到了这些数据之后,我立刻想到了一点子:基于标准普尔指数观察的500家公司的股价,用深度学习模型来预测标准普尔500指数。
把玩这些数据并用TensorFlow在其上建立深度学习模型是很有趣的,所以我决定写下这篇文章:预测标准普尔500指数的简易TensorFlow教程。你将看到的不是一个深入的教程,更多的是从高层次来讲解TensorFlow模型的重要构成组件和概念。我编写的Python代码并没有做专门的性能优化但是可读性还可以。下载我使用的数据集
注意:本文只是基于TensorFlow的一个实战教程。真正预测股价是非常具有挑战性的,尤其在分钟级这样频率较高的预测中,要考虑的因素的量是庞大的。
导入数据集
我们的团队将抓取到的股票数据从爬虫服务器上导出为CSV格式的文件。该数据集包含了从2017年四月到八月共计n=41266分钟的标准普尔500指数以及500家公司的股价。
|
|
数据是经过清洗准备好的,这意味着指数数据和股票数据是遵循LOCF(Last Observation Carried Forward)方法的,所以文件中不包含任何的缺失值。
可以通过pyplot.plot('SP500')来快速查看标准普尔500指数的时间序列。
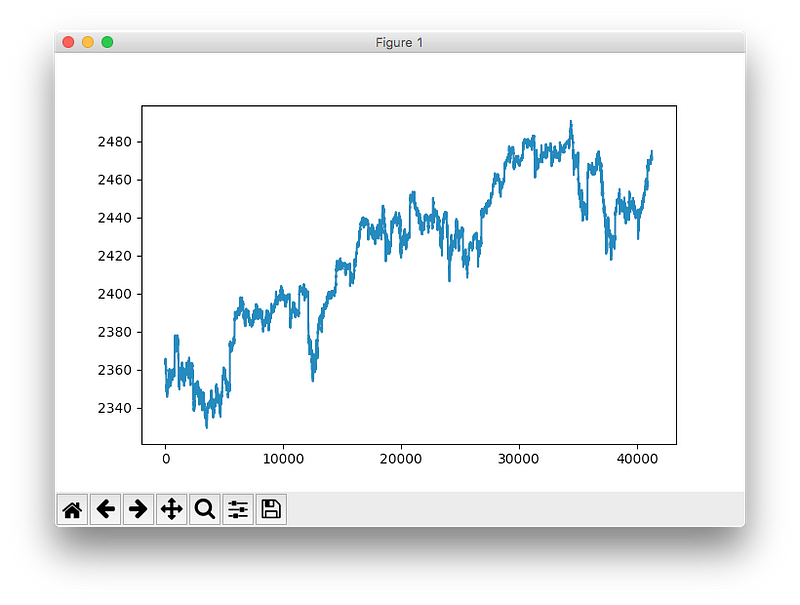
注意:这里展示的是标普500指数的领先(lead),也就是说其值是原始值在时间轴上后移一分钟得到的。因为我们要预测的是下一分钟的指数而不是当前的指数,所以这一操作是必不可少的。
准备训练集和测试集数据
原始数据集被划分为训练集和测试集。训练数据集包含了整个数据集的80%。注意这里的数据集划分不是随机划分得到的,而是顺序切片得到的。训练数据集是从2017年的4月到大约7月底,测试数据集则为到17年8月底的剩余数据。
|
|
时间序列的交叉验证方法有很多,像有无refitting或其他像time series bootstrap resampling的精细概念的滚动预测(rolling forecasts)。后者(time series bootstrap resampling)中的重复样本是考虑时间序列的周期性分解的结果,这是为了使模拟采样同样具有周期性的特征而不是单单复制采样值。
数据缩放
大多数的神经网络都受益于输入值的缩放(有时也有输出值)。为什么呢?因为大多数神经网络的激励函数都是定义在[0, 1]区间或[-1, 1]区间,像sigmoid函数和tanh函数一样。虽然如今线性整流单元已经被广泛引用于无界的激活值问题中,但是我们还是选择将输入输出值做统一的缩放。缩放操作可以通过sklearn中的MinMaxScaler轻松实现。
|
|
备注:应当仔细考虑好什么数据要在什么时候被缩放。一个常见的错误是在训练集和测试集划分前进行特征缩放。为什么这样做是错误的呢?因为缩放的计算需要调用数据的统计值(像数据的最大最小值)。当你在真实生活中进行预测时你并没有来自未来的观测信息,所以相应地,训练数据特征缩放所用的统计值应当来源于训练集,测试集也一样。否则,在预测时使用了包含未来信息往往会导致性能指标向好的方向偏移。
TensorFlow简介
TensorFlow是一个非常棒的软件,是深度学习和神经网络计算框架中的领头羊。它的底层后端是用C++编写的,通常通过Python来进行控制(还有R语言版的TensorFlow,由RStudio维护)。TensorFlow用图来描述底层的计算任务,这种方法使得用户可以通过表征数据,变量和操作的元素组合得到的计算图来指定相应的数学操作。由于神经网络实际上就是数据和数学操作的图,TensorFlow可以完美地应用于神经网络和深度学习,可以看下面给出的一个简单例子(取自作者的博文:Deep learning introduction)
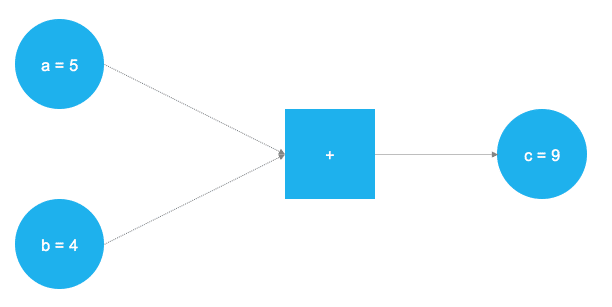
上图中两个数字要完成加和的操作。两个加数被存储在两个变量a和b当中,他们的值流入了正方形节点,即代表他们完成相加操作的位置。加和的结果被存储在另一个变量c中。事实上,a,b和c都可以被视为占位符。任何被填入a,b的数字将在完成加和操作后存入c中。这就是TensorFlow的工作原理,用户通过变量和占位符来定义模型(神经网络)的抽象表示。随后,占位符被实际的数字填充并开始进行实际的运算。下面的代码实现了上面简单的计算图。
|
|
在引入TensorFlow的库之后,两个占位符可以以tf.placeholder()的方式定义,对应上面图示中左侧两个蓝色的图形。随后通过tf.add()来定义数学加法操作,运算的结果为c = 9。当建立占位符之后,可以用任意的整数值a,b来执行计算图。当然,以上的问题不过是一个简单的示例而已,真正神经网络中的图和运算要复杂得多。
占位符
正如上面所说,所有的过程都从占位符开始。为了拟合模型,我们需要定义两个占位符:X包含模型输入(在T = t时刻500个成员公司的股价),Y为模型输出(T = t + 1时刻的标普指数)。
占位符的shape分别为[None, n_stocks]和[None],意味着输入为二维矩阵,输出为一维向量。设计出恰当的神经网络的必要条件之一就是清楚神经网络需要的输入和输出维度。
|
|
None值代表着我们当前不知道每个批次中流经神经网络的观测值数量,所以为了保持该量的弹性,我们用None来填充。稍后我们将定义控制每个批次中观测样本数量的变量batch_size。
变量
除了占位符,TensorFlow中的另一个基本概念是变量。占位符在图中用来存储输入数据和输出数据,变量在图的执行过程中可以变化,是一个弹性的容器。为了在训练中调整权重和偏置,它们被定义为变量。变量需要在训练开始前进行初始化。变量的初始化稍后我们会单独讲解。
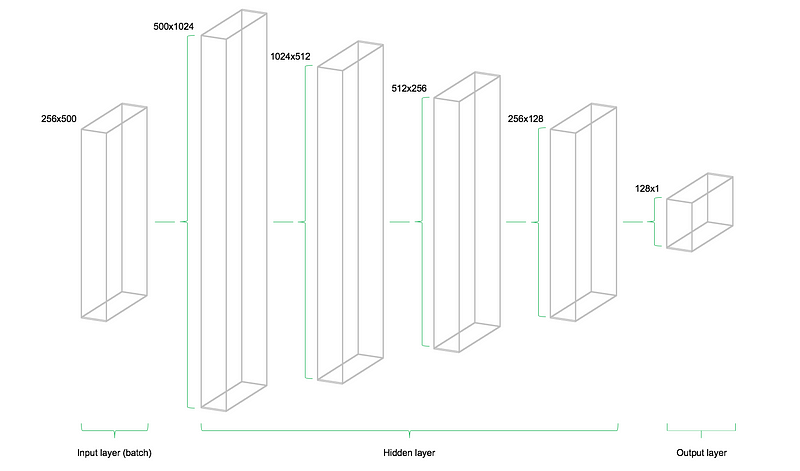
我们的模型包含四个层。第一层有1024个神经元,比输入变量的两倍还要多一点。紧接在后面的隐藏层是前面一层的一半,即后面层的神经元个数分别为512,256和128。每层中神经元数量的减少也意味着信息量的压缩。当然还有其他的神经网络结构,但是不在本文的讨论范围当中。
|
|
清楚输入层,隐藏层和输出层的变量对应的维度是非常重要的。在多层感知机的经验法则中(MLPs,本文就是按照该准则设计的网络),前一层权重的维度数组中的第二个元素与当前层中权重维度数组的第一个元素数值相等。听起来可能有些复杂,但是为了使当前层的输入作为输入传入下一层,这样的法则是必要的。偏置的维度等于当前层权重维度数组中的第二个元素,对应当前层中神经元的数量。
设计网络架构
在定义了所需的权重和偏置变量之后,网络的拓扑结构即网络的架构需要被确定下来。在TensorFlow中,即需要将占位符(数据)和变量(权重和偏置)整合入矩阵乘法的序列当中。
除此之外,神经网络中是经过了激活函数的转换的。激活函数是神经网络架构中非常的元素之一,在非线性系统中尤其如此。目前已经有很多中可供使用的激活函数,本文中的模型选用了最常用的整流线性单元(ReLU)。
|
|
下面的图形说明了网络架构。模型一共包含了三个主要的组件:输入层,隐藏层和输出层。图示的结构被称为前馈网络,前馈意味着从左侧输入的数据将径自向右传播。与之相对的网络结构如recurrent neural networks(RNN)允许数据流在网络结构中反向传播。
损失函数
网络的损失函数可以根据网络的预测值和训练集中的实际观测值来生成度量偏差程度的指标。在回归问题当中,最常用的损失函数为均方误差(MSE)。均方误差计算的就是预测值和目标值的误差平方值的平均值。基本上任何可微函数都可以用于计算预测值和目标值之间的偏差程度。
|
|
但是,在我们的问题中,MSE展示出了一些更有利与解决我们问题的特性。
优化器
优化器负责训练过程中调整网络的权重和偏置的关键操作。这些操作中包含着梯度运算,梯度方向对应的就是训练过程中最小化网络损失函数的方向。稳定而又高效的优化器是神经网络中深入研究的课题之一。
|
|
这里我们使用Adam优化器,目前它是深度学习中默认的优化器。Adam的全称为Adaptive Moment Estimation,可以视为其他两个优化器AdaGrad和RMSProp的结合。
初始化器
初始化器用于在训练前初始化网络的权重。由于神经网络是利用数值方法进行训练,所以优化问题的起始点是能否找到问题的最优解(或次优解)的关键因素之一。TensorFlow中内置了多种优化器,每个优化器使用了不同的初始化方法。这里我使用的是默认的初始化器之一——tf.variance_scaling_initializer()。
|
|
注意:在TensorFlow的计算图中,不同的变量可以定义不同的初始化函数。不过在大多数情况下统一的初始化函数就可以满足要求了。
拟合神经网络
在定义了网络的占位符,变量,初始化器,损失函数和优化器之后,模型需要进入正式的训练过程。通常我们使用minibatch的方式进行训练(小的batch size)。在这种训练方式中,我们从训练集中随机抽取n = sample_size的数据样本送入网络进行训练。训练集被划分为n / batch_size个批次并按顺序送入网络。这时占位符X和Y参与了这一过程,它们分别存储输入值和目标值并作为输入和目标送入网络。
样本数据X将在网络中传播直至输出层。到达输出层后,TensorFlow将把模型的当前预测值与当前批次的实际观测值Y进行比较。随后,TensorFlow将根据选择的学习方案对网络参数进行优化更新。权重和偏置更新完毕后,下一批采样数据将再次送入网络并重复这一过程。这一过程将一直持续至所有批次的数据都已经送入网络。所有的批次构成的一个完整训练过程被称为一个epoch。
当达到训练批次数或者用户指定的标准之后,网络的训练停止。
|
|
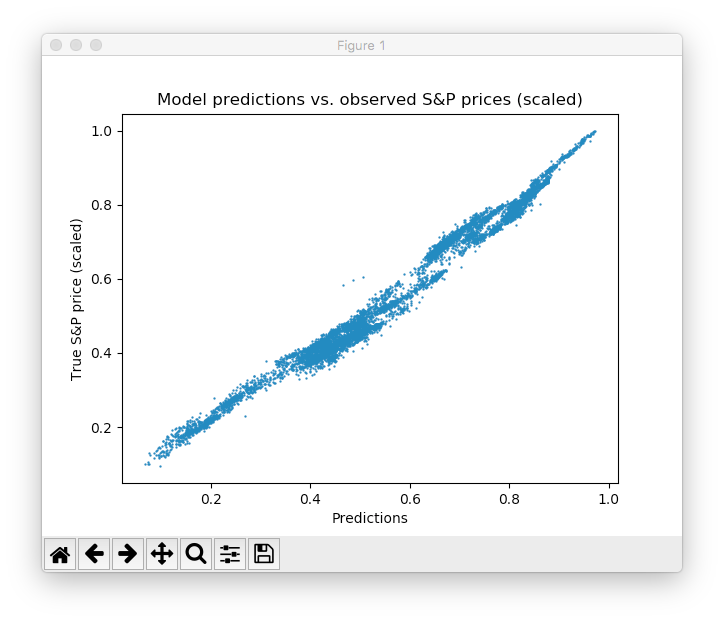
每隔5个批次的训练,我们用测试集(网络没有在这些数据上进行训练)来评估一次模型的预测性能并进行可视化。我们特意将每个节点的图像到处至磁盘制作了一个视频来展示训练的过程。可以看到模型很快习得了原始时间序列的形状和位置并且在一定的epochs后可以达到比较准确的预测值。这真是太好了!
可以观察到模型先是迅速习得了时间序列的大致形状,随后继续学习数据中精细结构。这与Adam学习方案为了避免越过最小优化值而不断降低学习率是相互照应的。在10个epochs后,我们完美地拟合了训练数据!最终的MSE只有0.00078(注意到我们的数据是缩放过的,所以这个值其实已经很小了)。在测试集绝对误差的占比等于5.31%,表现不错。注意:这只是测试集上的效果,并能代表实际场景中的性能。
这里再给出一些可以进一步提升结果的方法:规划网络层数和神经元个数,选择不同的初始化和激活方案,引入神经元的dropout层,early stopping等等。除此之外,换用其他类型的深度学习模型,比方说RNN也许可以在任务上达到更优的性能。在此我们不做讨论,读者可以自行尝试。
总结与展望
TensorFlow的发布是深度学习研究的一个里程碑。它的灵活性和良好的性能使研究者可以借助它完成一系列复杂的网络结构以及其他机器学习算法。不过,与Keras或Mxnet的高层级API相比,TensorFlow高度的灵活性是以增加模型建立的时间周期为代价的。尽管如此,我仍然认为TensorFlow会在神经网络和深度学习的理论研究和实际应用中走向标准化。我们的很多顾客已经开始使用TensorFlow并用它来开发项目,我们在STATWORX上的数据科学顾问也越来越频繁地使用TensorFlow进行研究和开发。看过了Google对TensorFlow的未来规划后,我觉得有一件事被遗忘了(从我的观点来看),就是利用TensorFlow作为后端去设计和开发神经网络的标准用户界面。当然,可能Google已经在做了:)
本文的代码可以从Github上下载,如果觉得译文有何问题欢迎邮件探讨 1208397343@qq.com

